Economic projections are collected from each member of the Board of Governors and each Federal Reserve Bank president four times a year. This project extracts and plots the projections in combination with the latest data.
Latest report can be found here.
Code available on github.
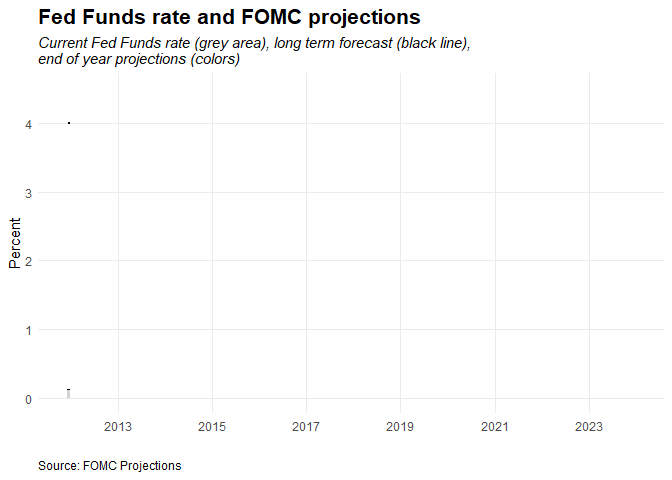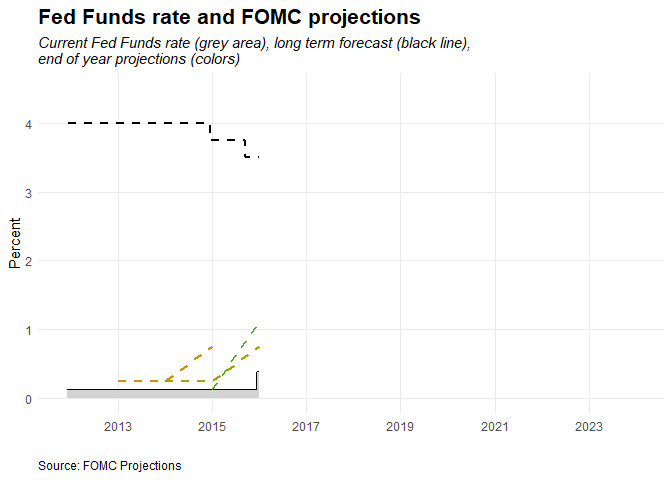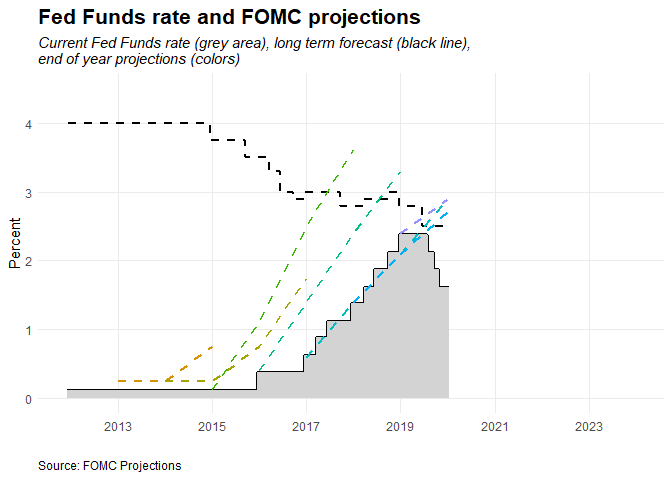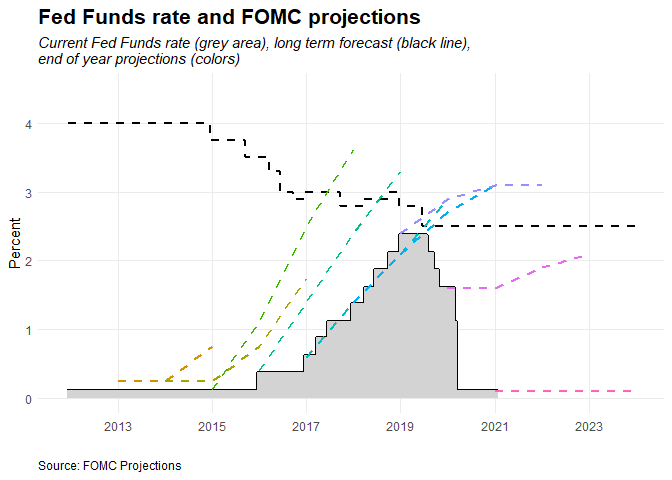
Below summarizes the steps taken in this project.
Methodology
The approach of this project is pretty straight forward - at least in theory. Extract all the FOMC Projections -> plot it. However, it is as usual easier said then done, especially when formats differs over time which typically makes the case for some extra coding and the easy-to-follow structure are not so easy anymore.
Side note: My approach for web scraping are to always add a delay when there are many pages that will be parsed (like it is in this case) and to save the data as .csv files. This makes it possible to reuse the data without unneccessary scraping, and also getting the data from other scripts easy.
Technologies
For this project, R is the program used. Please see a short description for each script below followed by some example code.
parseProjections.r parsing all FOMC Projections from 2015-09 until present, and December projections between 2011, 2013 and 2014. Formats before 2015 is pretty messy and irregular, but after 2015 they are cleaner (kudos Fed).
getData sources the latest data from BEA, BLS and from extracted Fed Funds rate. Both BEA and BLS have excellent API:s to source data. However, at the time being, for data from BLS I´m using Rvest. Disclaimer: BLS and BEA cannot vouch for the data or analyses derived from these data after the data have been retrieved from BLS and BEA.
index.rmd runs the scripts and imports the .csv files. Also some additional data wrangling and creating a plot function. The markdown renders a report.
Libraries used
Show
library(tidyverse)
library(rvest)
library(stringr)
library(gganimate)
library(gifski)
library(lubridate)
library(httr)
library(devtools)
library(bea.R)
parseProjections.r
Show
#####################################################################################################
### Libraries ###
#####################################################################################################
library(rvest)
library(tidyverse)
library(stringr)
#####################################################################################################
### Function for parsing ###
#####################################################################################################
parse_tables <- function(projections) {
base_url = "https://www.federalreserve.gov"
url = paste(base_url, projections, sep="")
parse_projections <- read_html(url)
df <- parse_projections %>%
html_nodes("table") %>%
html_table(fill = TRUE)
#"Normal" tables: After sep 2015
if (special_tables == 0) {
#Get table one
df <- df[[1]]
# due to that tables are a bit different.
if (df[1,1] == "") {
colnames(df) <- df[1,]
df <- df[-1,]
}
#convert first row to shared columnname
names(df) <- paste(names(df), df[1, ], sep = "_")
#delete first row
df <- df[-1,]
#pivot longer
df <- df %>%
pivot_longer(!1, names_to = "names", values_to = "values")
#divide the created column name
df <- df %>% separate(names, c('des', 'forecast_period'), sep="_")
#rename first column
df <- rename(df, variable = 1)
}
#Special tables: 2011-2014
if (special_tables == 1) {
#This depends on which minutes, year
date = as.numeric(gsub("\\D", "", substr(projections, 1, 40))) ##hummz
if (date == 20131218) {
df <- df[[6]]
}
if (date == 20141217) {
df <- df[[6]]
}
if (date == 20111213) {
df <- df[[9]]
}
#calculate median, needs to ungroup it
df <- df %>%
pivot_longer(!1, names_to = "forecast_period", values_to = "values")%>%
rename(rate = 1)%>%
na.omit(values)%>%
uncount(values)%>%
group_by(forecast_period)%>%
summarize(values = median(rate))
df$values <- as.character(df$values)
}
return(df)
}
#####################################################################################################
### Parse all projection links efter 2015 ###
####################################################################################################
url_links = list(
"https://www.federalreserve.gov/monetarypolicy/fomccalendars.htm"
# "https://www.federalreserve.gov/monetarypolicy/fomchistorical2016.htm",
)
projection_links = character()
for (each in url_links) {
parse_links <- read_html(each)
links <- parse_links %>% html_nodes("a") %>% html_attr("href")
links <- links[which(regexpr('.htm', links) >= 1)]
links <- links[which(regexpr('fomcprojtabl', links) >= 1)]
#print(each)
projection_links <- c(projection_links, links)
}
#Add links for 2015 (not on same page as for others)
projection_links <- c(projection_links, "/monetarypolicy/fomcminutes20151216ep.htm")
projection_links <- c(projection_links, "/monetarypolicy/fomcminutes20150917ep.htm")
##Special links
projection_links_specials = list(
"/monetarypolicy/fomcprojtabl20131218.htm",
"/monetarypolicy/fomcminutes20141217epa.htm#figure2", ###special
"/monetarypolicy/files/FOMC20111213material.htm") ###even more special
#####################################################################################################
### Create an empty data frame ###
#####################################################################################################
proj_table <- data.frame(matrix(ncol = 5, nrow = 0))
#provide column names
colnames(proj_table) <- c('variable', 'des', 'forecast_period', 'values', 'date')
#####################################################################################################
### Iterates all projection links and parse the tables ###
#####################################################################################################
#non specials (after 2015)
for (projections in projection_links) {
special_tables = 0
Sys.sleep(sample(3:9, 1, replace=T))
df <- parse_tables(projections)
df <- df %>%
mutate(date = as.numeric(gsub("\\D", "", projections)))
proj_table <- bind_rows(proj_table, df)
}
#specials (before 2015)
for (projections in projection_links_specials) {
special_tables = 1
Sys.sleep(sample(3:9, 1, replace=T))
df <- parse_tables(projections)
df <- df %>%
mutate(date = as.numeric(gsub("\\D", "", substr(projections, 1, 40))),
variable = "Federal funds rate",
des = "Median1"
)
proj_table <- bind_rows(proj_table, df)
}
#####################################################################################################
### Some additional cleaning and wrangling, write table ###
#####################################################################################################
if (".copy" %in% names(proj_table)){
proj_table <- proj_table %>%
select(-.copy)
}
write.table(proj_table, "data//projections_table.csv", sep=",")
getData.r
Show
#####################################################################################################
### Get Economic Data ###
#####################################################################################################
### Source for PCE inflation and GDP data are BEA. BEA has an excellent API that is used. https://apps.bea.gov/API/signup/index.cfm
### Source for Unemployment data is BLS. BLS also has a great API but for the moment I´m using Rvest.
### Source for Fed Funds rate are my github.
#BLS.gov cannot vouch for the data or analyses derived from these data after the data have been retrieved from BLS.gov.
#####################################################################################################
### Libraries ###
#####################################################################################################
library(httr)
library(devtools)
library(bea.R)
library(tidyverse)
library(stringr)
library(lubridate)
library(rvest)
#####################################################################################################
### Get Fed Funds rate ###
#####################################################################################################
fedFunds <- read.table(
"https://raw.githubusercontent.com/cnordenlow/text-mining-fomc/main/Data/fedFundsRate.csv",
sep=",", header=TRUE)
#Change dates
fedFunds <- fedFunds %>%
mutate(date = as.Date(gsub("\\D", "", date), format = "%Y%m%d"))
#Arrange
fedFunds <- arrange(fedFunds, date)
fedFunds <- fedFunds%>%
filter(bound == "lower_bound")%>% ###Just using the lower bond in case the indata file have missing values for lower or upper bound. THe problem will be easier to handle with a fill if I only use the lower_bound and adding 0.125
select(-bound)%>%
mutate(rate = round(rate + 0.125,2))%>%
mutate(LineDescription = "Federal funds rate")
#####################################################################################################
### Get Inflation and GDP data ###
#####################################################################################################
#Individual code comes from BEA when you register.
beaKey <- "xx"
#beaSearch('Personal consumption expenditures (PCE)', beaKey)
#Inflation
beaSpecs <- list(
'UserID' = beaKey ,
'Method' = 'GetData',
'datasetname' = 'NIPA',
'TableName' = 'T20804',
'Frequency' = 'M',
'Year' = '2011, 2012,2013,2014,2015,2016,2017,2018,2019,2020',
'ResultFormat' = 'json'
);
beaPayload <- beaGet(beaSpecs);
inflation_data <- beaPayload %>%
select(-c("TableName", "SeriesCode", "LineNumber", "METRIC_NAME", "CL_UNIT", "UNIT_MULT"))%>%
pivot_longer(!LineDescription,
names_to = "des",
values_to = "values")%>%
#Fix dates
mutate(des = str_sub(des,-7,-1))%>%
mutate(year = sub("\\M.*", "",des))%>%
mutate(month = str_sub(des,-2,-1))%>%
mutate(date = paste(year,month, sep="-"))%>%
mutate(date = as.Date(paste(date,"-01",sep="")))%>% #convert to dateformat
mutate(date = as.Date((date) + months(1) - days(1)))%>% #change to end of month
select(LineDescription, date, values) %>%
#Calculate YoY chg
arrange(date)%>%
group_by(LineDescription) %>%
mutate(rate = round((values - lag(values, n = 12, default = NA)) / lag(values, n = 12, default = NA) * 100,2)) %>% #YoY
#mutate(MoM = round((values - lag(values, n = 1, default = NA)) / lag(values, n = 1, default = NA) * 100,2)) %>% #MoM
#Select PCE
filter(LineDescription %in% c("Personal consumption expenditures (PCE)", "PCE excluding food and energy"))%>%
arrange(date)%>%
select(-values)
# GDP
beaSpecs <- list(
'UserID' = beaKey ,
'Method' = 'GetData',
'datasetname' = 'NIPA',
'TableName' = 'T10111',
'Frequency' = 'Q',
'Year' = '2011, 2012,2013,2014,2015,2016,2017,2018,2019,2020',
'ResultFormat' = 'json'
);
beaPayload <- beaGet(beaSpecs);
gdp_data <- beaPayload %>%
select(-c("TableName", "SeriesCode", "LineNumber", "METRIC_NAME", "CL_UNIT", "UNIT_MULT"))%>%
pivot_longer(!LineDescription,
names_to = "des",
values_to = "values")%>%
#Fix dates
mutate(des = str_sub(des,-6,-1))%>%
mutate(year =str_sub(des,1,4))%>%
mutate(month = as.numeric(str_sub(des,-1,-1)) * 3)%>%
mutate(date = paste(year, month, sep="-"))%>%
mutate(date = as.Date(paste(date,"-01",sep="")))%>% #convert to dateformat
mutate(date = as.Date(date) + months(1) - days(1))%>% #change to end of month
select(LineDescription, date, values) %>%
rename(rate = values)%>%
arrange(date)%>% #YoY
filter(LineDescription %in% c("Gross domestic product (GDP)"))
#####################################################################################################
### Get Unemployment Data ###
#####################################################################################################
url = "https://www.bls.gov/charts/employment-situation/civilian-unemployment-rate.htm"
#fomcprojections
parse_projections <- read_html(url)
labor_data <- parse_projections %>%
html_nodes("table") %>%
html_table(fill = TRUE)
labor_data <- labor_data[[1]]
labor_data <- labor_data %>%
mutate(month = substr(Month, 1, 3))%>%
mutate(year = str_sub(Month,-4,-1))%>%
mutate(month = match(month,month.abb))%>%
mutate(date = paste(year,month, sep="-"))%>%
#mutate(date = paste(year,match(df$month,month.abb),sep="-"))%>% #change month abr to index
mutate(date = as.Date(paste(date,"-01",sep="")))%>% #convert to dateformat
mutate(date = as.Date(date) + months(1) - days(1))%>% #change to end of month
select(date, Total)%>%
rename(rate = Total)%>%
mutate(LineDescription = "Unemployment rate")
#####################################################################################################
### Merge Data tables ###
#####################################################################################################
###Create dataframe with dates from 2011
dataTable <- data.frame(
date = seq(as.Date('2011-12-01'), Sys.Date(), by = 'days')
)
dataTable <- bind_rows(dataTable, fedFunds)
dataTable <- bind_rows(dataTable, inflation_data)
dataTable <- bind_rows(dataTable, gdp_data)
dataTable <- bind_rows(dataTable, labor_data)
dataTable <- arrange(dataTable, date)
dataTable <- dataTable %>%
pivot_wider(date, names_from = LineDescription, values_from = rate)%>%
select(-"NA")
dataTable <- dataTable %>% fill(names(dataTable))
dataTable <- dataTable %>%
pivot_longer(!date, names_to = "LineDescription", values_to = "rate")
df <- df %>%
mutate(date = as.Date(as.character(date)))
dataTable <- dataTable %>%
filter(date > "2011-12-01")
write.table(dataTable, "data//dataTable.csv", sep=",")index.rmd
Show
knitr::opts_chunk$set(echo = TRUE)
#####################################################################################################
### Libraries ###
#####################################################################################################
library(tidyverse)
library(rvest)
library(stringr)
library(gganimate)
library(gifski)
library(lubridate)
#####################################################################################################
### Sourcing parsing scripts ###
#####################################################################################################
#source('getData.r')
###source scraping
#source('parseProjections.R')
#####################################################################################################
### Importing .csv files with parsed projection tables ###
#####################################################################################################
proj_table <- read.table(
"data//projections_table.csv",
sep=",", header=TRUE)
dataTable <- read.table(
"data//dataTable.csv",
sep=",", header=TRUE)
#####################################################################################################
### Some additional cleaning and wrangling ###
#####################################################################################################
#Remove spaces in "des" so all looks the same
proj_table$des <- gsub('\\s+', '', proj_table$des)
##Get longer run, and put as an column to link it to meetingdates
longer_run <- proj_table %>%
filter(forecast_period %in% c("Longer run", "Longer Run"))%>%
mutate(date = as.Date(gsub("\\D", "", date), format = "%Y%m%d"))%>%
rename(longer_run = values)#%>%
# filter(des %in% c("Median 1", "Median1"))%>%
# select(variable, longer_run, date)
proj_table <- proj_table %>%
mutate(projection = date)%>%
filter(!forecast_period %in% c("Longer run", "Longer Run"))%>%
mutate(date = as.Date(gsub("\\D", "", date), format = "%Y%m%d"))%>%
mutate(forecast_period = as.Date(paste(forecast_period, 12, 31, sep = "-")))%>%
# mutate(values = as.numeric(as.character(values)))%>% ##as they are factors you need as.characters before as.numeric
mutate(meeting_month = months(date))%>%
mutate(projection_year = substr(projection, 1, 4))#%>%
# filter(des %in% c("Median 1", "Median1"))
proj_table$forecast_period <- as.Date(proj_table$forecast_period, format = "%Y-%m-%d")
proj_table$date <- as.Date(proj_table$date, format = "%Y-%m-%d")
#####################################################################################################
#####################################################################################################
###
### Data wrangling and plot function
###
#####################################################################################################
#####################################################################################################
plotFunction <- function(variable_name, LineDescription_name, start_date, title_text, subtitle_text, caption_text) {
temp <- proj_table %>%
filter(variable %in% variable_name)%>%
filter(meeting_month %in% c("december"))%>%
filter(des %in% c("Median1"))%>%
mutate(values = as.numeric(as.character(values))) ##as they are factors you need as.characters before as.numeric
####Always include the last if it is the current year
last_projection <- proj_table %>%
filter(date == max(date))%>%
filter(year(date) == year(Sys.Date()))%>%
filter(variable %in% variable_name)
#Merge
temp <- rbind(temp, last_projection) %>%
select(-date)
##Merge historical data
df <- dataTable %>%
filter(LineDescription == LineDescription_name)
##convert temp dates to dates:D
df <- df %>%
mutate(date = as.Date(as.character(date)))
temp <- merge(df, temp, by.x = "date", by.y ="forecast_period", all = TRUE)
#change na projections to ""
temp$projection_year[is.na(temp$projection_year)] <- ""
#####################################################################################################
### Merge with longer run Projection ###
#####################################################################################################
temp_longer_run <- longer_run %>%
filter(variable %in% variable_name)%>%
filter(des %in% c("Median 1", "Median1"))%>%
select(-c("variable", "des"))
temp <- merge(temp, temp_longer_run, by=c("date"), all.x = TRUE)
temp <- arrange(temp, date)
temp <- temp %>%
fill(longer_run, .direction = "down")
#temp$longer_run[is.na(temp$longer_run)] <- ""
temp$longer_run <- as.numeric(as.character(temp$longer_run))
####Calculate max and min for the plot
max_y <- max(
max(temp$rate, na.rm = TRUE),
max(temp$values, na.rm = TRUE),
max(temp$longer_run, na.rm = TRUE)
) + 0.5
min_y <- min(
min(temp$rate, na.rm = TRUE),
min(temp$values, na.rm = TRUE),
min(temp$longer_run, na.rm = TRUE)
)
if (min_y < 0) {
min_y =min_y - 0.5
}
if (min_y >= 0) {
min_y = 0
}
##to be able to change start date
temp <- temp %>%
filter(date > start_date)
#plotting
p <- ggplot(temp, aes(x = date, y = rate)) +
geom_line(size = 1)+
geom_area(fill = "lightgrey")+
geom_line(aes(y=longer_run), linetype="dashed", size=1)+
geom_line(aes(y=values, group = projection_year, color = projection_year), linetype="dashed", size=1)+
# geom_line(aes(y=values, group = projection_year), linetype="dashed", size=1)+
theme_minimal() +
theme(legend.position="none",
legend.title = element_blank(),
plot.caption=element_text(hjust=0),
plot.subtitle=element_text(face="italic"),
plot.title=element_text(size=16,face="bold"))+
labs(x="",y="Percent",
title=title_text,
subtitle=subtitle_text,
caption=caption_text
)+
scale_x_date(date_breaks = "2 year",
date_labels = "%Y")+
theme(
panel.grid.minor = element_blank()
)+
ylim(min_y, max_y)
}