FOMC Minutes are usually a hot topic on the financial markets. There are plenty of observeres trying to break down what they said, and what they really meant.This project aims to give colour on both the actual context but also (hopefully) the underlying meaning and sentiment. With the field of text mining, this projects breaks down the Minutes into multiple areas making plots out of words.
Latest report can be found here.
Code available on github.
Below summarizes the steps taken in this project.
Methodology
The approach of this project are as follows.
Words and topics are divided into bag of words of its meaning (e.g. the word “strong” may consists of [“strong”, “stronger”, “strongest”, “strengthen”]). All bag of words dictionaries are located in the iterateMinutes.py.
All web parsing is done using BeautifulSoup package. The code first parse all .htm pages with the url of “Minutes” in it for the years of interest. Then, a second loop parse all the (chosen) Minutes for the text mining. In both parsing steps, there are a time delay of a couple of seconds.
Text are divided into sentences as well as words. For some parts we use the full sentences, and for some cleaned sentences and words are used. NLTK package is used.
All sentences are iterated where it checks for the different bag of words and then counted, (e.g. if the word “stronger” is found in a sentence, the count adds one regardless of how many time strong is in the sentence.) For most topics, a second loop followed which counts negative and positive words in the same sentence to get the net sentiment for each topic.
R is used for some further calculations and Markdown for creating a report.
To be able to to compare Minutes by different length with each other, everything is set in relation to total the number of words or paragraph in their respective Minutes.
The purpose with the bag of words format is to being able to get part of sentences grouped for their meaning. E.g. for being able to find more colour on asset purchases (tapering amounts, reducing the program, increasing the program), it may not be sufficient to map a sentence with the word of “increase” and “asset purchase” in the same, but there a for some subjects meaningful to have longer parts of a meaning.
Technologies
For this project, both Python and R are used. Please see a short description for each script below followed by some example code.
fomcTopicDefinitions.py are definitions for different topics with bag of words. Also Loughran-McDonald dicitonary.
getFedFundsRate.py are parsing all chosen statements to get the Fed Funds rate for each meeting. It´s saved as an csv named fedFundsRate in subfolder Data.
iterateMinutes.py is the main loop for parsing and text mining all chosen Minutes. Each minutes are iterated in a for loop that extract word data. Everything is then joined in a table that is saved as a .csv saved in subfolder Data. The purpose of saving these files are to be able to put down more time on the plotting between meetings without needing to parse all Minutes each time.
r_plots.r is a script with a couple of plots that are reused multiple times in the Markdown report.
index.rmd is doing some additional data wrangling and producing the report.
runAllScripts.r can run all scripts together using Reticulate-package in R for running Python.
Example Python code for getting all Statements and Minutes
Both python scripts follows the same structure with one loop getting all statements and Minutes, followed by a loop that iterates each Statement and Minutes. See github for full code.
#######################################################################################
### Get links for statements (get links for Minutes works the same.) ###
#######################################################################################
urls = ['https://www.federalreserve.gov/monetarypolicy/fomccalendars.htm',
'https://www.federalreserve.gov/monetarypolicy/fomchistorical2014.htm',
'https://www.federalreserve.gov/monetarypolicy/fomchistorical2013.htm',
'https://www.federalreserve.gov/monetarypolicy/fomchistorical2012.htm',
'https://www.federalreserve.gov/monetarypolicy/fomchistorical2011.htm',
'https://www.federalreserve.gov/monetarypolicy/fomchistorical2010.htm'
]
statements_list_url = []
for url in urls:
time.sleep(random.uniform(3,7))
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
##find all links with the word monetary (minutes for minutes)
links = soup.select("a[href*=monetary]") #find the word monetary in href
#links = soup.select("a[href*=minutes]") #find minutes in href #for Minutes
#print(links)
for link in links:
if "a.htm" in link.get('href'):
statements_list_url.append(link.get('href')) ##get all href that are htm page
#####################################################################################################
### Main loop that iterates all statements. The loop for iterating Minutes works in the same way ###
#####################################################################################################
number = 100 # Number of statements to parse
for each in statements_list_url[0:number]:
time.sleep(random.uniform(3,7))
url2 = 'https://www.federalreserve.gov' + each #get url for each side
html = urllib.request.urlopen(url2).read()
soup = BeautifulSoup(html, 'html.parser')
text = soup.get_text() ##get all text
...Clean data...
#Get Fed funds Rate
rate_changes_temp = dict()
match = 0
for sen in sentences: ##Iterates all sentences looking for below
if "federal funds rate" in sen and "target" in sen and "to" in sen and "percent" in sen:
# if "federal funds rate" in sen and "target" in sen and "to" in sen and "percent" in sen and "decided" in sen or "decision" in sen and not "voting against" in sen:
target = "percent"
sen_words = word_tokenize(sen)
for i,w in enumerate(sen_words):
if w == target:
if sen_words[i-7] != "inflation" or sen_words[i-6] != "inflation" or sen_words[i-5] != "inflation" or sen_words[i-4] != "inflation" or sen_words[i-3] != "inflation" or sen_words[i+3] != "inflation" or sen_words[i+2] != "inflation" or sen_words[i+1] != "inflation":
if i>0:
lower = sen_words[i-3]
upper = sen_words[i-1]
if "0" in lower or "/" in lower or "-" in lower or "‑" in lower or lower.isnumeric():
if "0" in upper or "/" in upper or "-" in upper or "‑" in upper or upper.isnumeric():
if match == 0: ##only take the first correct match
#print(lower)
temp = lower #return un-convertedRate if the convertRate dosen´t work
temp = convertRate(lower) ###convertRate converts the rate
rate_changes_temp["lower_bound"] = temp
#print(upper)
temp = upper #return un-convertedRate if the convertRate dosen´t work
temp = convertRate(upper)
rate_changes_temp["upper_bound"] = temp
match = match + 1
rate_changes_temp = pd.DataFrame(rate_changes_temp.items(), columns=['bound', "rate"])
rate_changes_temp['date'] = minutes_x
rate_changes = pd.concat([rate_changes, rate_changes_temp])
rate_changes.to_csv("data/fedFundsRate.csv", encoding='utf-8', index=False)#Write to CSV
Example code topic definitions / bag of words (fomcTopicDefinitions.py)
For iterateMinutes, a bag of words format is used to being able to classify different words with the same (give or take) meaning to each topic. See github for full code.
##########################################################################################
### Classifications of topics, negative & positive words, intentifiers etc. ###
##########################################################################################
#Topics are built as dictionaries in a bag of words/sentence format.
topics = {'broad_topics' :
{
'Economy' : ["economy", "economic", "gdp"],
'Labor' : ["labor", "employment", "unemployment", "payroll", "participation rate"],
'Consumer' : ["consumer", "consumption", "household"],
'Inflation' : ["inflation", "pce", "cpi", "core"],
'Manufacturing' : ["manufacturing", "business", "production", "productivity","businesses","investment spending"],
'Housing' : ["housing", "house", "home", "housing-sector", "residential"],
'Commodities' : ["energy", "commodity", "commodities", "oil","gas", "gasoline"],
'Trade' : ["export", "trade", "import"],
'Demand' : ["demand"],
'Foreign' : ["foreign", "international", "china", "europe", "india", "canada", "brexit", "emerging"]
},
'policy_topics' :
{
'Federal funds rate' : ["federal funds rate", "target range"],
'Yield curve control' : ["yct", "YCT", "yield caps or target", "capped", "yield curve control","yield caps", "target interest rate", "cap rate", "capping longer term interest", "cap shorter-term"],
'Asset purchases' : ["asset purchase", "asset purchases", "asset holding", "holding of "],
'Repo operations' : ['repurchase agreement', 'reverse repurchase', "rrps", "repo facility", "rrp","repo operation", "repurchase agreement operation", "overnight reverse repurchase"],
'Forward guidance' : ['forward guidance', "expect"],
#'Excess reserves' : ["excess reserve", "ioer"],
'Negative interest rates' : ["negative interest", "negative rates"],
#'Swap agreements' : ["swap arrangement", "swap agreement"],
'Liquidity facilities' : ["liquidity facility", 'liquidity swap', "liquidity and lending"]
#'ample reserve' : ["ample reserve"]
}
}
intensifiers = ["very", "terribly", "exceptionally", "extremely", "significant", "extreme", "significantly", "rapid", "rapidly", "sharp", "severely","substantial", "substantially", "terribly", "sharply"] ###ny
in_deep_topics = {
'asset_program' : {
'Size' : ["size"],
'Composition' : ["composition"],
'Pace' : ["pace"],
'Keep same size' : ["rolling out at auction all principal", "roll over at auction all principal payments", "rolling over at auction all principal payment", "continue reinvesting all principal", "ending the reduction", "rolling over maturing treasury securities at auction", "existing policy of reinvesting principal payment"],
'Increase size' : ["increase its holdings","expanding", "increase the system open market account holdings of treasury", "increase holdings of", "increasing"],
'Reduce size' : ["decrease", "reduce", "reduction", "that exceed", "unwind", "withdrawal"],
'Taper amounts' : ["taper", "tapering", "billion per month rather than", "reduce the pace of asset purchase", "net purchases cease"],
'Guidance' : ["guidance"],
'Longer maturity' : ["longer maturity", "lengthening the maturity"]
},
'inflation' : {
'Symmetric' : ["symmetric"],
'Compensation' : ["compensation"],
'Core' : ["core"],
'Term premium' : ["term premium"],
'Wages' : ["wages", "wage"],
'Energy' : ["energy"],
'Long-term expectations' : ["long-term", "longer-term"],
"Average inflation targeting" : ["average"]
},
'labor' : {
'Slack ' : ["slack"],
'Job gains' : ["job gain"],
'Supply' : ["supply"],
'Participation rate' : ["participation rate"],
'Unemployment' : ["unemployment"],
'Maximum employment' : ["maximum employment", "full employment"]
}
}
###Example of how it is used.
#In deeper topic asset purchase. The purpose of this script is to get in deeper context of FOMC thoughs on their asset purchase program.
temp_dict = dict()
for sen in sentences:
if "asset purchase" in sen or "asset purchases" in sen or "asset program" in sen or "holdings of" in sen or "securities holdings" in sen:
#for key, value in asset_program.items(): #for each key and value in sub dictionaries
for key, value in in_deep_topics['asset_program'].items(): #for each key and value in sub dictionaries
# for key, value in asset_program.items(): #for each key and value in sub dictionaries
if any(item in sen for item in value):
temp_dict[key] = temp_dict.get(key, 0) + 1
#print(sen)
else:
temp_dict[key] = temp_dict.get(key, 0) + 0 ###To get the word in the dataframe. Its an answer that it wasent included.
temp_dict = pd.DataFrame(temp_dict.items(), columns=['subject', "frequency"])
temp_dict['date'] = minutes_x
temp_dict['category'] = "in_deep_asset_program"
temp_dict['additional'] = "count_words"
temp_dict['frequency_share'] = (temp_dict['frequency'] / len(sentences))*100
minutes_all_tables = pd.concat([minutes_all_tables, temp_dict])
Example code R plots
For those plots used multiple time, the script r_plots.r is created a couple of plots as functions which are sourced from RMarkdown. See github for full code.
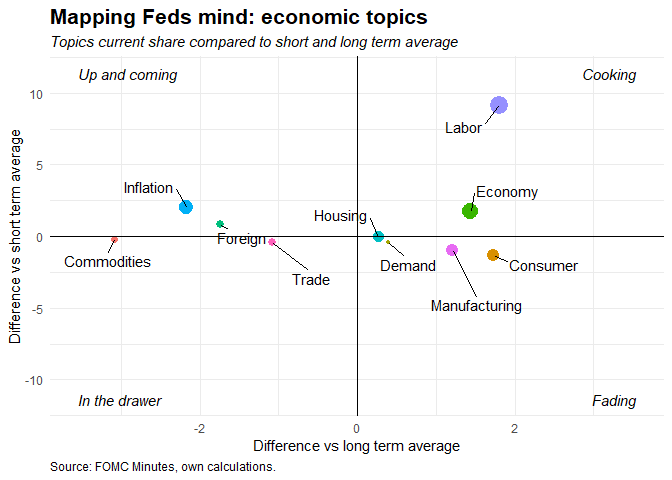
plot_bubble <- function(temp, x_axis, y_axis,bubble_size, c_title, c_subtitle, c_caption, c_x_axis, c_y_axis){
p <- ggplot(data=temp, aes(x = x_axis, y = y_axis)) +
geom_point(aes(size=bubble_size, color=subject)) +
geom_text_repel(aes(label=subject),min.segment.length = 0, seed = 42, box.padding = 0.75)+
geom_hline(yintercept=0) + geom_vline(xintercept=0) +
theme_minimal() +
theme(legend.position="bottom",
plot.caption=element_text(hjust=0),
plot.subtitle=element_text(face="italic"),
plot.title=element_text(size=16,face="bold"))+
labs(x=c_x_axis,y=c_y_axis,
title=c_title,
subtitle=c_subtitle,
caption=c_caption)+
theme(legend.position = "none")+
annotate(geom="text", x=max(abs(temp$x_axis))*1.15, y=max(abs(temp$y_axis))*1.25, label="Cooking", color="black",size=4, fontface="italic",hjust = 1)+
annotate(geom="text", x=max(abs(temp$x_axis))*1.15, y=-max(abs(temp$y_axis))*1.25, label="Fading", color="black",size=4, fontface="italic",hjust = 1)+
annotate(geom="text", x=-max(abs(temp$x_axis))*1.15, y=-max(abs(temp$y_axis))*1.25, label="In the drawer", color="black",size=4, fontface="italic",hjust = 0)+
annotate(geom="text", x=-max(abs(temp$x_axis))*1.15, y=max(abs(temp$y_axis))*1.25, label="Up and coming", color="black",size=4, fontface="italic",hjust = 0)
}
Creating plot in RMarkdown.
Step 1: Import CSV-files and doing some additional calculations.
library(tidyverse)
library(lubridate)
library(slider)
library(dplyr, warn.conflicts = FALSE)
library(lubridate, warn.conflicts = FALSE)
library(ggrepel)
###source plots
source('r_plots.R')
#setting overlaps for ggrepel
options(ggrepel.max.overlaps = Inf)
df <- read.table(
"data\\fomcMinutesSummary.csv", ##på detta sätt läser den ur aktuell mapp
sep=",", header=TRUE)
#Change dates
df <- df %>%
mutate(date = as.Date(gsub("\\D", "", date), format = "%Y%m%d"))
#arrange
df <- arrange(df, date)
#number each minutes
temp <- df%>%
select(date) %>%
distinct() %>%
mutate(num = 1:n())
df <- merge(df, temp, by = "date", all.x = TRUE)
###sliding mean
df <- df %>%
group_by(subject, additional) %>%
mutate(avg_st = slide_index_dbl(frequency, num, mean, .before=3, .after=-1,.complete=T)) %>% ##dont include the current
mutate(avg_lt = mean(frequency))%>%
mutate(avg_st_share = slide_index_dbl(frequency_share, num, mean, .before=3, .after=-1,.complete=T))%>%
mutate(avg_lt_share = mean(frequency_share))%>%
mutate(ma_3m = slide_index_dbl(frequency, num, mean, .before=2, .after=0, .complete=T))%>%
mutate(ma_3m_share = slide_index_dbl(frequency_share, num, mean, .before=2, .after=0, .complete=T))
#exclude first three rows to only include when 3m_moving is on
df <-df %>%
filter(num > 3)
#one minute lag
df <- df %>%
group_by(subject, additional) %>%
mutate(previous = lag(frequency, n = 1, default = NA)) %>%
mutate(previous_share = lag(frequency_share, n = 1, default = NA))
df <- df %>%
mutate(chg_previous = frequency - previous)%>%
mutate(chg_avg_st = frequency - avg_st)%>%
mutate(chg_avg_lt = frequency - avg_lt)%>%
mutate(chg_previous_share = frequency_share - previous_share)%>%
mutate(chg_avg_st_share = frequency_share - avg_st_share)%>%
mutate(chg_avg_lt_share = frequency_share - avg_lt_share)
###Get Fed Funds Rate
df2 <- read.table(
"data\\fedfundsRate.csv",
sep=",", header=TRUE)
#Change dates
df2 <- df2 %>%
mutate(date = as.Date(gsub("\\D", "", date), format = "%Y%m%d"))
#arrange
df2 <- arrange(df2, date)
df2 <- df2%>%
filter(bound == "lower_bound")%>%
select(-bound)
#Merge
df <- merge(df, df2, by ="date", all.x = TRUE)
df <- as.data.frame(df)
df[is.na(df)] <- 0
Step 2: Use the dataframe df with dplyr-conditions for filtering.
temp <- df %>%
filter(category == "broad_topics")%>%
filter(additional == "count_words")%>%
filter(date == max(df$date))%>%
select(subject, frequency_share, chg_avg_st_share, chg_avg_lt_share)%>%
mutate(y_axis = chg_avg_st_share,
x_axis = chg_avg_lt_share,
bubble_size = frequency_share)
c_title = "Mapping Feds mind: economic topics"
c_subtitle = "Topics current share compared to short and long term average"
c_caption = "Source: FOMC Minutes, own calculations."
c_x_axis = "Difference vs long term average"
c_y_axis = "Difference vs short term average"
p <- plot_bubble(temp, x_axis, y_axis, bubble_size, c_title, c_subtitle, c_caption, c_x_axis, c_y_axis)
p